I don't want to know IPs: encryption in TORRENTDYNE
Why and how I designed a custom encryption scheme for TORRENTDYNE
A few days ago I released TORRENTDYNE, a BitTorrent implementation checker. While working on it, I hit a wall: how do you make a service like this useful AND appropriately private? I ended up using a heap of cryptographic tools, but it did take me some time to figure out. I haven't seen too many clean slate encryption design reports, so here's my contribution.
Diagnosing BitTorrent Connectivity
P2P protocol deployments are hard to diagnose without a known good implementation. There are dozens of BitTorrent client implementations of varying quality, running over quirky residential connections. A centralised, well instrumented, specification-compliant service giving instant feedback is something I wish I had while writing a toy BitTorrent implementation, so of course I started writing my own.

The scope predictably crept, and the tool I wanted became both a clean slate test tracker and a test client wrapped into a web interface that I hope will some day do the same SSL Labs did to TLS: raise the bar across the ecosystem.
This is when I realised I have a problem: to give usable reports, I need the reports to include IP addresses. But I really don't want to store the addresses! Unlike SSL Labs, I'm dealing with residential IPs, which are definitely private data.
Asymmetric Boxing
The best I can do is to only hold IP addresses in memory and only for as long as they are needed to perform connection testing. I implemented BitTorrent stuff in Rust, and secrecy was just perfect for IPs. It encapsulates sensitive data, prevents it from being accidentally logged, and makes accessing it very explicit, which is exactly what I want. But how do I provide users with test reports that include their IP addresses? I can immediately send reports to the browser, but what if someone wants to open it later or share it with a friend? I want to store IPs in a form that I myself can't access, but users should be able to.
It sounds very much like asymmetric encryption: a type of encryption algorithm that has not one, but two keys (usually called "public" and "secret"), with things being encrypted with one half of the pair only being decryptable with the other half. With an algorithm like that I can do the following:
- Generate a pair of public and secret key in the browser, save both into browser's local storage
- Send the public key to the server during anonymous "pre-registration"
- Run the test, using BitTorrent announces to obtain IP addresses to test
- Encrypt all reported IP addresses with user's public key, write them into the database, get IDs for the addresses
- Use database IDs instead of the actual IPs in test reports
- When showing the report, send encrypted IPs to the browser
- Decrypt the IPs in the browser with the secret key that has never left the browser
I know it's hard to follow so here's a hard to follow image:
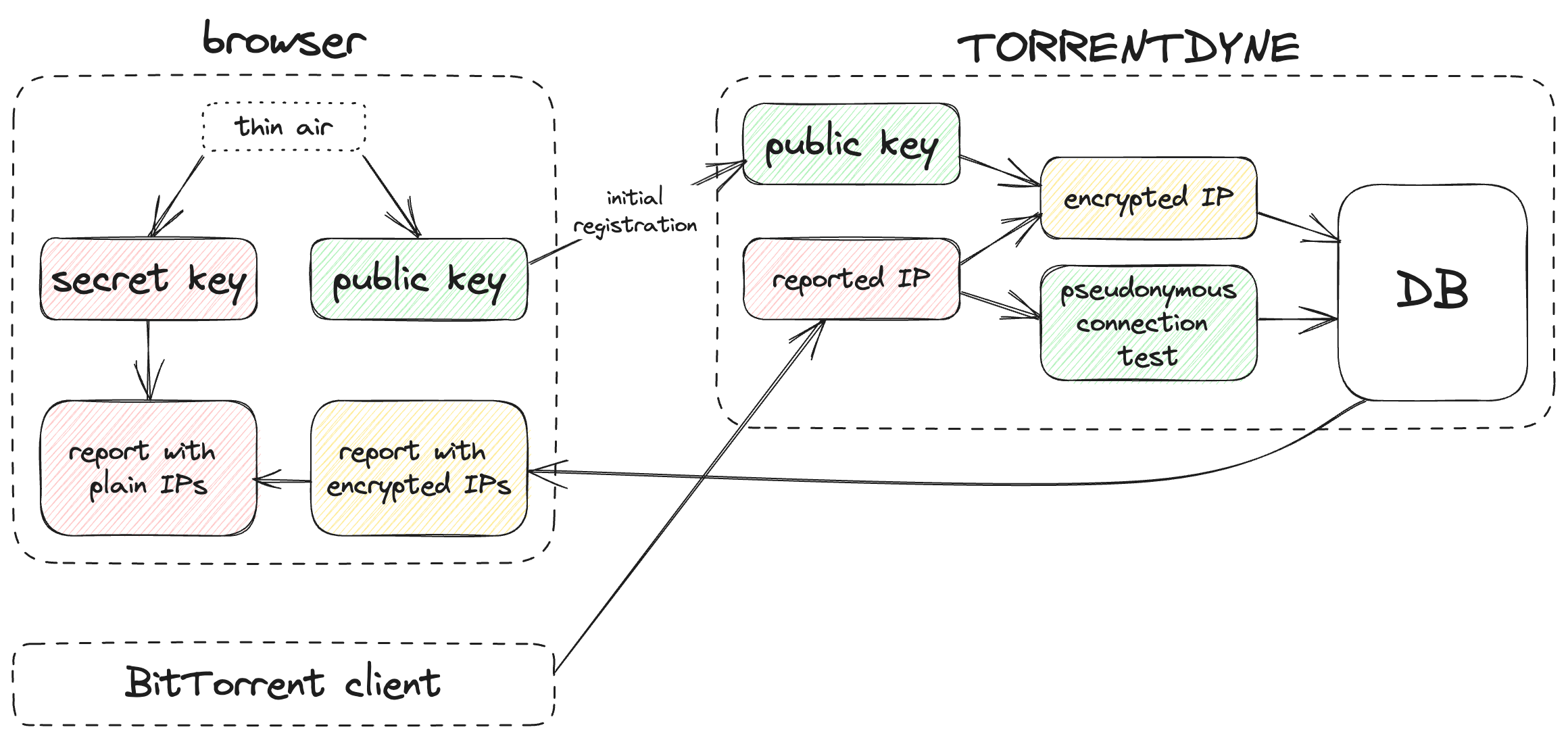
This works quite nicely:
- IP addresses are present in the test report if the user's browser has the secret half of the key pair
- I don't store any IP addresses that I can access
- Reports don't include any private data accessible without the secret key, so users can freely share their test reports by URL, which is convenient
Unfortunately, ideas aren't code, so I needed an actual encryption library and not just jumbled notes in a notepad.
Making cryptographic choices is a well known minefield1, but thankfully NaCl exists and provides a simple
API with all choices made by someone knowing what they are doing2. NaCl was ported to all sorts of platforms
and languages, so I just grabbed TweetNaCl.js for the browser and
NaCl compatibility layer for the Rust backend, using the Box API that fits the problem perfectly.
There's still a practical problem though: what should happen if the user changes their browser? How should they recover their secret key, which is long and impossible to remember?
Symmetric Login
I considered storing the key on the server, encrypted with a symmetric cipher. Too bad that it seems to be a chicken-and-egg problem, because I still need an encryption key for the cipher.
Wait, not if I use a password! I can't use an arbitrary key with asymmetric encryption (public and secret keys need to be generated together in a specific way), but symmetric encryption algorithms take just one arbitrary key! If a user encrypts their secret keys with their password and I store it on the server, it all works out: secret keys are backed up in encrypted form on the server and returned to the browser on login, where they are decrypted using the user's password and put into local storage. Everything's back to where it started.
Next step is to look at the actual API. NaCl's Secretbox hints at a small road bump: it takes a
32-byte big Uint8Array, not a string. Fair enough, normally you want your symmetric cipher key to be a long,
uniformly random byte sequence (probably of a given length), while text passwords are just strings
of any length and are often not very random.
Thankfully there's just the tool for this: KDFs, Key Derivation Functions. KDFs take strings
and return very random-looking byte sequences of a given length. SHA-256
can work as a KDF in a pinch, but KDFs specifically designed for passwords such as
scrypt, bcrypt,
or argon2 are much better. I chose scrypt just because there is
a good JS implementation available.
This means I now have a way to back up and recover the key without knowing it, which is great. What's not so great is that I also need a password for login, because I have a "normal" login with Django (Django is lovely for "normal" web bits). This makes it possible for me to capture and use this password to decrypt the secret key and thus decrypt the IP addresses! Clearly I shouldn't just use the provided password for login, but using two different passwords would be pretty inconvenient.
Instead, I just run the KDF twice with two different "salt" values ("salt" is a random non-secret value that adds randomness to KDF output), use one as a symmetric encryption key, and another as a "password". This makes it impossible for me to recover the original password or the symmetric key that was used to encrypt the secret key.
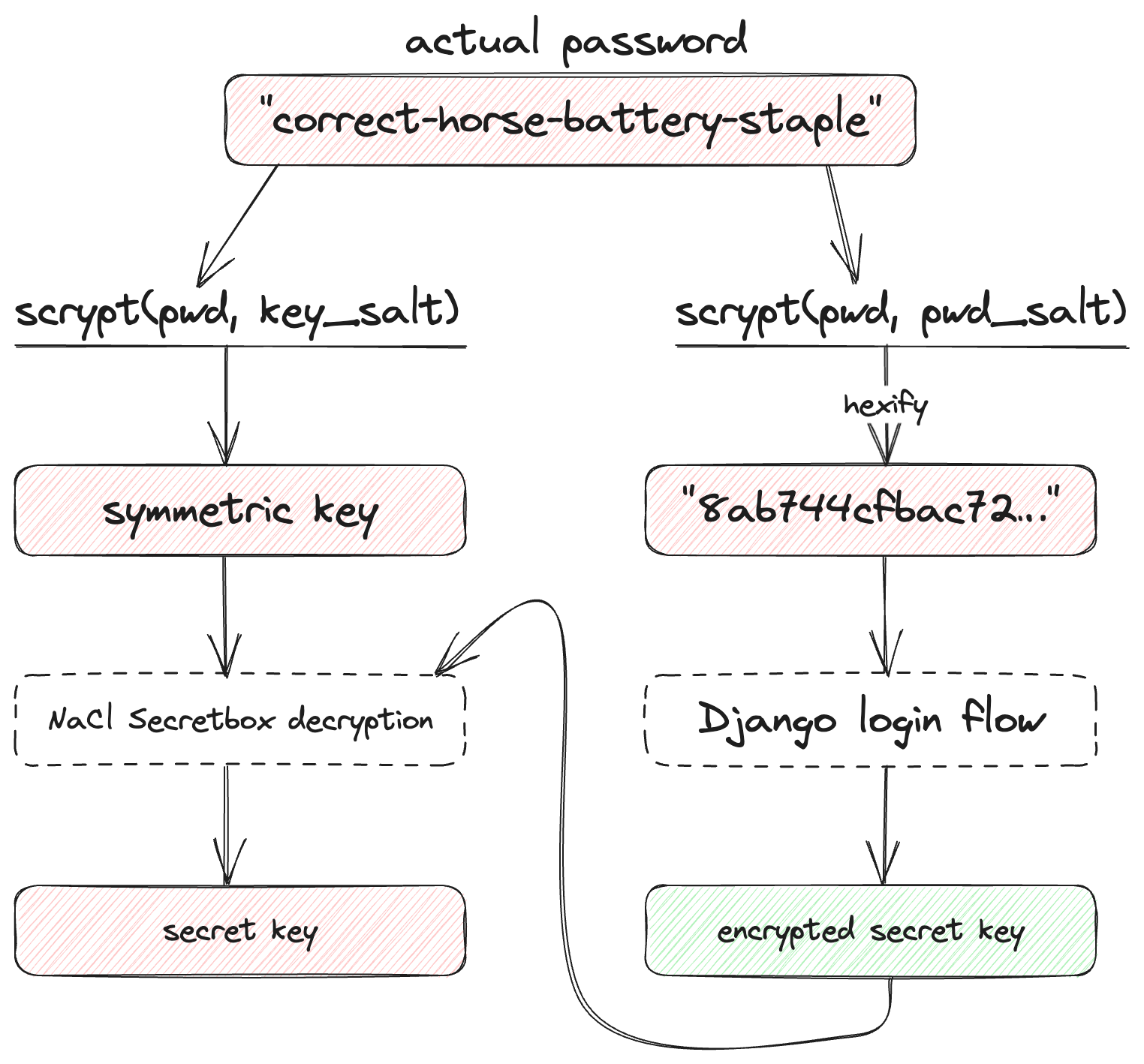
Now everything is nicely tied up and end-to-end encrypted, relying only on scrypt-reinforced password
to stay secure. Registration works similarly, but this post is too narrow to contain it.
Except it's not enough, because I want it to be good. I have nothing good to show when the IP address
can't be decrypted. I can show a trimmed hex representation of the encrypted value, but it's not a good UI.
Box takes a unique per-encryption value, so when the same IP is independently encrypted twice
it has two different encrypted representations3. To make test reports more usable in their "anonymous" form,
I want a given IP address to have the same representation in a given test report.
Never hash IP addresses
Some people, when confronted with the problem above, would think "I know, I'll use a hash." Now they still have the same problem, because hashing is useless for this.
Here is what hash functions do: they map a very large (or infinite) space of all possible byte sequences (or strings) into a much smaller, very finite space of all possible hashes in a pseudo-random, unpredictable manner:
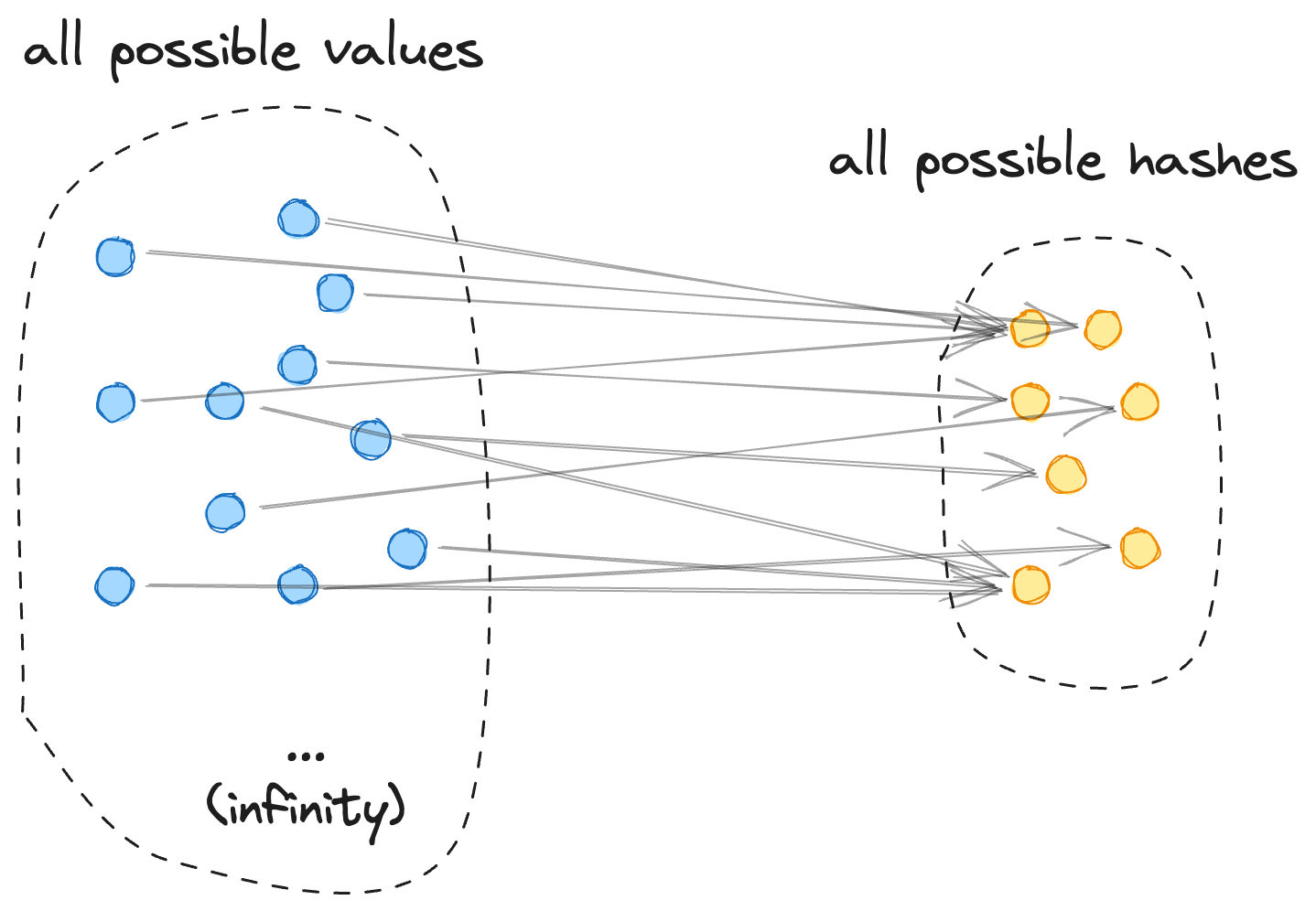
Here is what makes hashes "one way":
- we believe it's impossible to calculate the "inverse" of a hash function
- the space of all possible values is so big it's impossible to just try to hash them all
Both must be true for hashes to be impossible to "revert". However, IP addresses fail the second requirement! The total number of IPv4 addresses is about 4 billion, which can all be hashed in a few seconds, finding all addresses that have the given hash. When the number of all possible hashes is so much larger than the number of possible IP addresses, it's overwhelmingly likely that every hash value would correspond to at most one IP address4.
One possible defence is increasing ambiguity. I can trim the hash to a few bytes (I don't need many for a visual representation anyway) and expect many IP addresses to have the same trimmed hash value. Sadly, it's not a reliable way to anonymise, because hashing is pseudo-random and while some trimmed hash values might have hundreds of IP addresses corresponding to them, some might only have one.
The fundamental problem is that there are just not enough IP addresses for hashing to work. To meaningfully apply any one-way function to an IP address, I have to add some extra random data. There's a perfect tool for this: HMAC5.
Repurposing HMAC
MAC in HMAC means "message authentication code". Normally MACs are used to verify that a message was not tampered with and that whoever produced the MAC has the same (symmetric) secret key as the verifying party does. It's similar to a digital signature, but with just one symmetric key instead of a key pair. However, in this case I (ab)use HMAC completely differently: as a way to make hashes that are completely irreversible even for a small number of inputs after the key is thrown away. Given a key, HMAC is still constant and unique for a given IP address, just like normal hashes are.
When a test is being started, I generate a random HMAC key, which is as sensitive as the IP addresses themselves because if I know the key it's equivalent to just hashing IPs. Whenever an IP address is being encrypted and saved to the database, I also calculate an HMAC of the address, trim it for visual brevity, and save it next to the encrypted IP. When the test is finished, the key is thrown away.
This gives me unique identifiers for every IP address, stable for the duration of a test run, without compromising user privacy. Test reports are usable in their anonymous form and I'm finally satisfied that it's good.
Comments? Opinions? Feedback? Ping me at dan@dgroshev.com!
-
I very much recommend Dan Boneh's cryptography course and the cryptopals crypto challenges if you are curious to see why. ↩
-
Our lord, saviour, and oasis in the desert DJB. ↩
-
Which is what you actually want for your encrypted data! If someone observes your encrypted messages, letting them know that two messages are identical because their encrypted forms are the same would be bad. ↩
-
This is also why Facebook hashing uploaded PII like phone numbers to "anonymise them" is a joke. ↩
-
I suppose I could get away with simply hashing an IP address and a key together in this case as length extension attacks don't matter, but there is no reason not to use HMAC. ↩